Published
- 1 min read
Hashnode Sync
A CLI for syncing with Hashnode - Hashnode Hackathon Submission
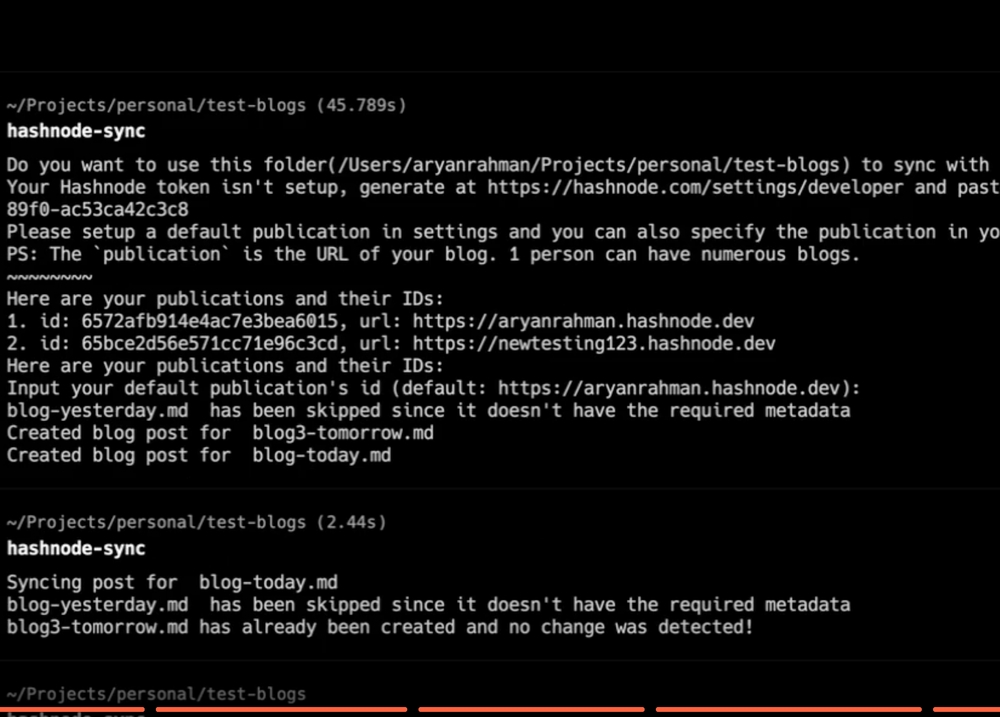
A CLI that syncs a folder of local markdown files to Hashnode. Built in a day for the Hashnode GraphQL hackathon to support a content-as-code blogging workflow.
TL;DR
- Content-as-code workflow: edit locally, run one command, post updates remotely.
- Uses a Proxy to auto-persist state whenever the config object changes.
Tech Stack: Node.js GraphQL npm
State that saves itself
The CLI needs to remember sync state between runs - which files were synced, their Hashnode IDs, content hashes. The typical approach: manual read/write calls everywhere.
Instead, the config object is wrapped in a JavaScript Proxy. Any property change automatically persists to disk:
function getSyncedJson(path) {
const obj = JSON.parse(fs.readFileSync(path))
return new Proxy(obj, {
set(target, property, value) {
Reflect.set(target, property, value)
saveJsonFile(path, target) // Auto-persist on any change
return true
}
})
}Now config.lastSync = Date.now() works without explicit save calls. This reduced state-management boilerplate.
Change detection
SHA-256 hashing on file content + metadata. Only files with changed hashes trigger API calls. If the hash matches, the file is skipped.
What it does
- Watches a folder of markdown files
- Detects new/changed/deleted posts
- Syncs to Hashnode via their GraphQL API
- One command:
hashnode-sync
Published on npm. Content-as-code workflow for blogs.