Published
- 3 min read
Custom URL Feature - Enterprise SaaS at Scale
Infrastructure-level feature work across CloudFront, Lambda@Edge, DynamoDB, that served 1M+ assets/day
Custom URLs sound like a small routing feature until your “URLs” are served behind CloudFront, across branded domains, and you can’t afford to break caching or ship a redirect loop to enterprise customers.
TL;DR
- Implemented an edge-first custom URL resolver (CloudFront + Lambda@Edge + DynamoDB) so branded vanity paths resolve without hitting the app unless they should.
- Built validation + guardrails to prevent collisions, reserved system paths, and “looks valid but breaks prod” edge cases.
- Shipped safely via monitoring + staged rollout (with a clean rollback path).
My role: Full Stack Software Engineer
Tech stack: AWS CloudFront · Lambda@Edge · DynamoDB · Python
Scale: ~1M+ assets/day with global edge routing behavior
What we built
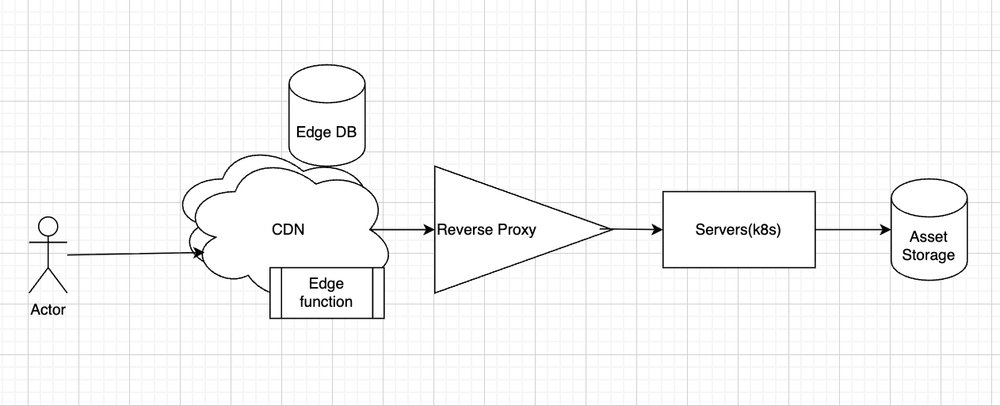
Users could create a vanity path like /summer-sale on a branded domain, and we served the correct underlying asset/page without major application-routing changes. The key detail: resolution had to happen at the CDN edge, not in the app.
The mental model that mattered:
request -> CloudFront -> Lambda@Edge (resolve) -> reverse proxy -> k8s -> S3/appConstraints that shaped the solution
- Branded domains + multiple tenants. A path isn’t unique unless you include the hostname. (
/abouton domain A might be valid, but reserved on domain B.) - Backwards compatibility. Existing “real” routes must keep working exactly as before.
- Reserved paths. System routes like
/api,/static,/admin, etc. must never be claimable. - Caching needs to stay sane. If every request becomes dynamic, cost and latency can regress quickly.
Scope I owned within team delivery
- Safe URL creation. Validation rules that blocked reserved paths and collisions (including “it exists but not as a custom URL” collisions).
- Edge resolution. A Lambda@Edge resolver that:
- Computes a stable lookup key (domain + path).
- Reads the mapping from DynamoDB.
- Rewrites the request to the internal target when it’s a match.
- Falls back cleanly when it’s not.
- CloudFront configuration. Picking the right event trigger, forwarding the minimum headers, and keeping caching predictable.
- End-to-end debugging. Tracing issues across CloudFront, Lambda@Edge logs, and k8s pods.
UI
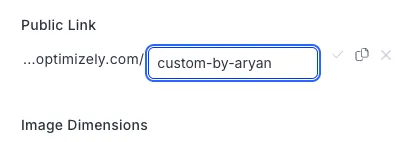
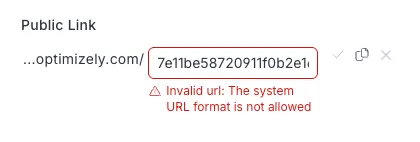
The feature is boring when it’s working, so here are the two states that actually mattered:
Valid mapping state:
Blocked/invalid state (example: GUID-like path / collision patterns):
One thing that went wrong (and what I changed)
The first version passed staging and then produced intermittent 404s in production. The root cause was a combination of edge caching behavior and subtle header-forwarding differences that changed cache-key behavior.
The fix was straightforward: tighten the cache key, forward fewer headers, and add explicit logging around “resolved vs passthrough” so the team could verify behavior without guessing.
Tradeoff I made on purpose
We could have built a richer matching engine (wildcards, regex, precedence rules). I kept it intentionally simple (exact path matches + strict validation), because complex URL rules become long-term support overhead in enterprise systems.
Outcome
- Shipped to enterprise clients without outages.
- Added docs and runbooks so teammates can find the right logs and execute rollback quickly.